There are many trust and safety challenges in the new generative AI technologies, but there is one area where they could increase trust and user empowerment. These technologies provide an opportunity to offer the kind of transparency that will allow meaningful control of how people use complex online systems, including control of privacy.
This opportunity comes from two observations: (1) that the biggest problem in privacy is explaining to the user how their data is used, and (2) that one of the notable abilities of LLMs (large language models) is to summarize complex data understandably.
Over the years working on Internet systems, I have seen big improvements in protecting privacy. Some of this improvement is driven by the increasing public awareness of the importance of privacy and the necessity for companies to address privacy if they want to maintain user trust. Some of this is driven by the need for regulatory compliance, initially with GDPR in Europe, but increasingly with new regulations in various countries and US states.
But what do companies actually do to respond to retain trust and keep in compliance? Let’s divide privacy protection measures into two categories: backend and frontend.
Backend privacy protection is where most of the effort has gone. Much of the work here is around data flows, identifying and controlling how personal data is transmitted through and stored in the complex infrastructure behind large modern Internet systems. While practically doing this can be a difficult engineering task, the requirements are generally well understood.
Frontend privacy protection is much more of an open problem. The areas of understanding and consensus are limited to a few areas such as what “dark patterns” should be avoided and how to create cookie consent UIs (which everyone hates). In particular, there remains the biggest unsolved problem, which is how to give people meaningful agency over how their data is used, given the systems are so complex that it is very difficult even for the engineers building and running the services to explain.
But now we see the opportunity. Explaining complex subjects is one thing that LLMs are good at.

One approach is, given an existing system that has personal data flowing through it, for a particular person using the system, we generate a comprehensive description of all their data and how it is used, perhaps in the context of a particular feature they are using. This raw description would be voluminous, highly technical, and perhaps might contain references to proprietary information, so it would be not at all useful or appropriate to display to the person. However an LLM, with an appropriate prompt, could summarize this raw dump in a way that could be safely and meaningfully displayed to the person. This could provide transparency, customized to the particular context. With different prompts, the LLM output format could be adjusted to match the reading level of the person, and to the size and formatting constraint of the part of the UI in which it is displayed.
This transparency is good, and it would help give a sense of agency to the person. But is there a way to take this further and additionally use LLMs to provide controls?
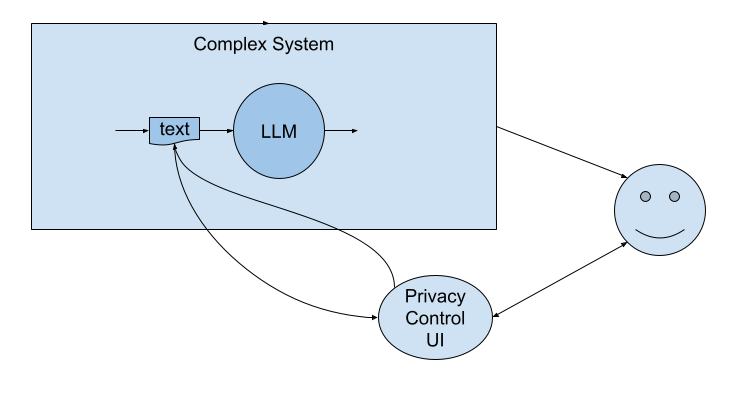
Well, yes, in some cases if an LLM is incorporated into the system and helps personalize the output, then we can take advantage of the fact that the “API” of an LLM is natural language. That means that somewhere deep in the data flow is some human-meaningful text that is being ingested into an LLM. So we have an opportunity to reveal that text to the person using the system and allow them to modify it, possibly by simply adding or modifying freeform natural language text.
Of course, there are many challenges and possible hazards to using LLMs in these ways. For the transparency proposal, LLMs can hallucinate and generate incorrect summaries of personal data which could be confusing or possibly disturbing to the person. Even if the summary is factual it could present it in a biased manner, for example using gender or racial stereotypes. There is also the possibility that the summary, even if correct and unbiased, could be alarming to the person, but that is arguably a case of “working as intended”: it is better for long-term trust for the person to learn this sooner rather than later, and to thus be able to take prompt action to control how their data is used.
I’m not aware of any such systems yet launched, but I’m hoping it will happen, and in so doing harness the power of generative AI to empower people to make the appropriate trade-offs in each context for how much personal data they want to be used in return for a particular benefit.