Last weekend I decided I wanted to learn how to use the OpenAI API to create an AI chatbot that ran on Mastodon. When I started I had several questions:
1.. How do I control the costs?
2. What is the architecture of this bot?
3. How do I use the Mastodon API?
4. How do I use the OpenAI API?
5. How to deploy?
6. How to I get people to use it?
Costs
Unlike some other personal projects, this one was going to cost money.
The OpenAI API charges per word*. That means, just in case this bot became very popular, I needed a way to throttle the usage to keep the costs within reasonable bounds for a hobby project.
Many of my other projects are websites that can be purely static front-end code, and I have deployed them for free on Netlify, GitHub Pages, or Firebase Hosting. But this project needs back-end execution, which is going to probably mean paying for it.
Architecture
A Mastodon bot is just some code running somewhere that uses the same Mastodon API that a user's Mastodon client code uses.
I could think of three possible places to run the code:
- On a server in my house. I have a Raspberry Pi I could use, or I could just run it on my laptop that I keep plugged in all the time.
- On a compute server in the cloud.
- In a Serverless Cloud function
I rejected #1, because my house is in a rural area with unreliable Starlink internet.
I was very tempted to try #3 because I used to work in Google Cloud building the infrastructure for serverless functions, but in the end, I decided it was more complex than I needed especially because I would also need to pay for a cloud scheduler.
In the end I chose #2, a cloud compute server. I already had one set up to host this blog, and even though it is one of the cheapest, least-powerful instance types, it was only running at a few percent of its capacity, so I could add the bot execution without any extra costs.
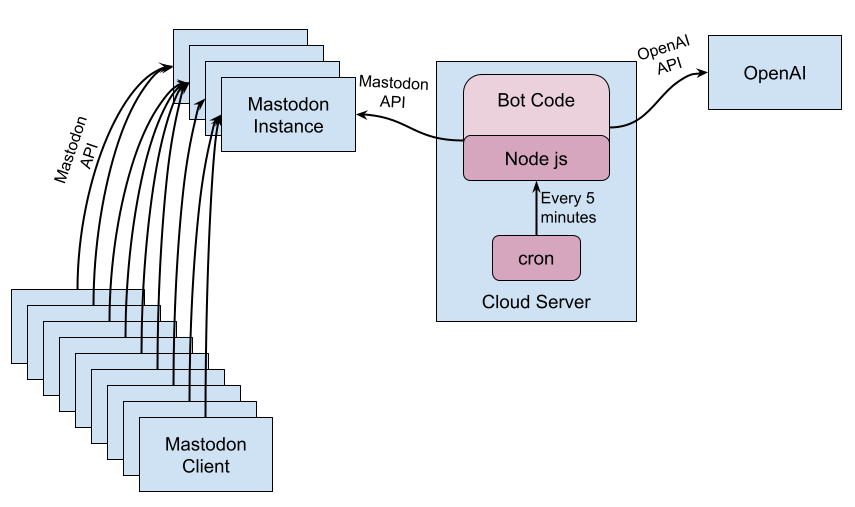
The bot is an executable, which has credentials to the @elelem@botsin.space account on the botsin.space Mastodon instance. The executable does not run continuously but is invoked once per post. Each time it is invoked it looks in its notifications to see if there are any “mentions”, that is, posts that include “@elelem@botsin.space”. If there are, it picks one and responds to it.
The executable is executed by cron every five minutes, so that means that the bot will respond to at most one post per five minutes, which naturally throttles the use and keeps the costs under control. If necessary I can adjust the cron frequency to trade off worst-case costs against the responsiveness of the bot.
The executable could have been written in any language, but I chose back-end (Node js) JavaScript because it was easy to use with both the APIs I would need to use.
The code is divided into three modules:
1. mastodon.js connects to Mastodon
2. llm.js connects to OpenAI
3. index.js is the top-level control flow
Mastodon API
I only needed to use a small part of the Mastodon API:
1. Read all notifications
2. Read a toot
3. Post a toot
4. Delete a notification
Initially, I tried using the megalodon library, but I could never get it to work. It has a TypeScript API which I somehow could not manage to call from JavaScript.
So in the end I just made my own XHR calls directly to the Mastodon REST API which is nicely documented.
const headers = {
Authorization: `Bearer ${accessToken}`
}
....
export const getToot = async (id) => {
const result = await (
await fetch(pp(`${baseUrl}/api/v1/statuses/${id}`), { headers })
).json()
if (result.error) {
throw new Error(result.error)
}
return {
statusId: result.id,
acct: result.account.acct,
inReplyToId: result.in_reply_to_id,
text: convert(result.content)
}
}
For example, above is my function to read a toot, given its ID. The pp function is from my passprint module. It returns its single argument but also logs it. For the rest of the Mastodon access code see the mastodon.js JavaScript file.
OpenAI API
This was the area that was new to me, and included my first taste of “prompt engineering”. The particular API I used is the “completion” API which exposes the basic functionality of the large language model (LLM) as a very sophisticated auto-complete.
await openai.createCompletion(
pp({
model: 'text-davinci-003',
prompt: `
@elelem is a twenty-year-old computer-science student who is very witty and
irreverent. She has a quirky sense of humor and a very dry wit. Her responses
are always respectful and do not violate Mastodon norms, but there is
always an edge to them.
The following is a Twitter thread with posts by @elelem and @${human}.
${thread}
@elelem:`,
temperature: 0.9,
max_tokens: 500,
top_p: 1,
frequency_penalty: 0.0,
presence_penalty: 0.6,
stop: ['@elelem:', '@elelem@botsin.space:', `${human}:`]
})
)
The way to turn this completion API into a chatbot is to add prelude text that specifies the “personality” of the bot and sets up a Mastodon thread structure to be completed by the LLM with one more response.
The thread variable is the text of the Mastodon thread that triggered this response. It is in the form:
@somename: some text
@anothername: some more text
...
I refer to it as a Twitter thread rather than a Mastodon thread in the prompt because I assume the LLM has had a lot more Twitter than Mastodon training material.
Deployment
I considered using one of the devops systems like Puppet or Ansible for deploying the code, but it seemed like overkill for a simple single-server deployment.
So instead I put all the code on GitHub, ssh to the production machine, clone the repo for the first deployment, and then do subsequent deployments by pulling from GitHub.
One issue with that model is that both the OpenAI API and the Mastodon API have secret keys that should not be in GitHub. So the code reads them from environment variables, and I have a non-checked-in file called secrets.env that sets the environment variables and is called from a wrapper run.sh script.
Because I was not using a proper devops system, I had to manually install Node (via nvm) and set up the crontab file.
*/5 * * * * PATH=/home/eobrain/.nvm/versions/node/v19.8.1/bin:$PATH /home/eobrain/elelem/run.sh >>/home/eobrain/elelem/cron.log 2>&1
The crontab line shown above, is a little hairy. The */5 * * * * specifies that the command that follows is executed every five minutes. The PATH=... sets up the execution environment for a particular nvm installation of Node. The 2>&1 redirects standard error to standard output so that they both get written out to the cron.log file.
Getting people to use it
To keep within the norms of a well-behaved bot, @elelem@botsin.space does not spam people by intruding into their timelines. Instead, it only responds to posts that explicitly mention it, including posts that reply to one of its posts.
But that means it is not very viral, and it is not clear to me how to get people to use it.
So far I have tried posting from my main @eob@social.coop account to draw attention to it, and I created an AI-generated avatar by giving the description in the prompt to DALL-E
If you want to try it out, simply mention @elelem@botsin.space in a toot.
* Actually per “token”, where tokens average about four characters each.